
들어가기에 앞서
요즘 들어 프론트엔드 개발에서 성능 개선 쪽에 조금 관심이 생기면서 '사용자는 우리가 생각한 타이밍보다 훨씬 빠르게 반응을 기대한다'는 걸 자주 느낍니다.
저도 그렇지만, 클릭을 통해 페이지 이동을 기다리는데 기대했던 데이터 대신 비어있는 화면이 잠깐이라도 나타나는 걸 참지 못하는 사용자가 꽤 많습니다. UX 관점에서야 당연한 이야기지만, 실제 구현에서 이와 같은 부분을 해결하려면 꽤 신경 써야 하는 부분이 많죠.
이런 고민을 가지고, 최근에는 Tanstack query와 Next.js 관련을 좀 더 공부하다보니 자연스럽게 'prepatching'이라는 키워드에 관심이 생겼습니다.
prepatching은 데이터를 필요로 하기 전에 미리 불러오는 전략으로, 단순히 API를 일찍 호출하는 게 아니라 렌더링 흐름이나 캐싱 전략까지 고민해야 하기 때문에 구조적인 접근이 필요합니다.
게다가 최근 Next.js를 사용하게 되면서 "Next.js는 서버 사이드 렌더링이 되는데. 굳이 prepatching이 필요한가?🤔" 하는 의문이 들었고 이를 Tanstack Query와 결합해서 어떻게 사용해야 좋을지도 함께 고민하게 되었습니다.
이번 글에서는 prepatching이란 무엇인지, 왜 필요한지, Next.js와 Tanstack Query를 활용해 어떻게 구현할 수 있는지를 하나씩 정리해보려 합니다.
"SSR이 있으면 다 되는 거 아니었어?" 하고 저와 같은 의문을 한 번이라도 가진 적 있으시다면, 이 글이 작은 힌트가 되길 바라며 글을 작성해 보겠습니다.

Prepatching이란?
Prepatching은 말 그대로 Pre-(미리) 패치하다. 즉, 데이터를 필요해지기 전에 미리 패칭 하는 전략입니다.
흔히 페이지 이동이나 특정 컴포넌트가 마운트 된 직후 데이터를 가져오는 경우가 많은데, 그 순간까지 기다리면 사용자 입장에서는 "왜 아직 아무것도 안 떠?🤨" 하고 체감 지연이 발생할 수 있습니다.
CSR 방식에서의 일반적 데이터 패칭 흐름
일반적으로 CSR(Client-Side Rendering) 기반 SPA에서는 다음과 같은 흐름으로 데이터가 패칭 됩니다.
- 사용자가 페이지 이동(eg. /profile 클릭)
- 해당 페이지 컴포넌트 마운트
- useEffect 등에서 API 호출 시작
- 데이터가 도착하면 렌더링 시작
이 경우 2-3 사이의 시간 동안에는 아무런 데이터가 없기 때문에 보통 로딩 스피너를 보여주거나, 비어있는 skeleton UI를 띄우는 식으로 UX를 보완합니다.
하지만 모두 알다시피, 이건 어디까지나 "없는 데이터"를 "있어 보이게" 하는 임시방편에 불과합니다.
체감 속도를 높일 수 있는 근본적인 해결책이 아니라는 거죠.
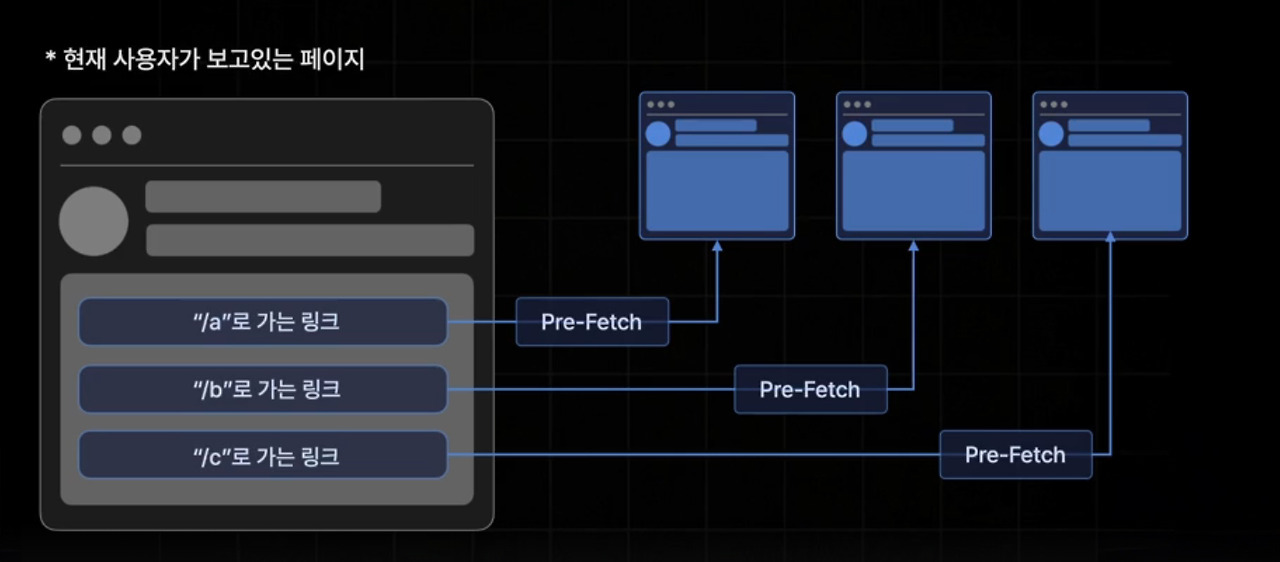
Prepatching의 핵심
핵심은 바로, 사용자가 이동하기 전에 미리 수행하는 것입니다.
예로 들자면 사용자가 마우스를 /profile로 이동하는 버튼 위에 올리는 순간에 미리 API를 호출하거나, 특정 페이지에 진입하기 전 공통적으로 필요한 데이터를 사전에 로딩해 두는 방식이죠.
패칭 타이밍을 바꿔서 실제로 보여줄 준비가 끝난 상태로 페이지를 넘겨주는 것이 바로 핵심입니다.
이렇게 하면 페이지가 전환될 때 이미 필요한 데이터가 캐시에 존재하게 되므로, 실제 화면 렌더링이 훨씬 빠르게 느껴지게 됩니다.
이런 전략은 물론, 데이터가 자주 바뀌지 않는 페이지나 예측 가능한 유저 플로우가 있는 경우에 효과적입니다.
물론 당연하게도! 단순히 fetch를 먼저 한다고 prepatching이라고 생각하면 안 됩니다.
오히려 캐싱 전략이나 쿼리 키 관리, 로딩 상태 관리 등 부가적 요소를 제대로 고려하지 않으면,
중복 요청이 발생하거나 기타 문제가 생기며 오히려 UX가 더 나빠질 수 있습니다.
왜 Prepatching이 필요할까?

사용자의 체감속도
예전, 성능에 대해서 잘 고려하지 않았을 때에는 데이터가 안 뜨면 그냥 로딩 스피너를 하나 박아두는 걸로 충분하다고 생각했습니다.
하지만 다양한 프로젝트를 경험해보고, 프론트엔드 개발자로서 모든 웹페이지를 이동할 때 이런 부분에 좀 더 관심을 갖고 살펴보다보니 스피너는 눈 가리고 아웅에 불과하다는 게 확실히 느껴졌습니다.
다음과 같은 순서로 페이지가 로딩된다고 가정해 보겠습니다.
버튼을 클릭함 → 화면이 바뀜 → 스켈레톤 UI(or 로딩 스피너) → API 요청 → 데이터 수신 후 렌더링
글로만 읽었을 때는 전혀 문제없는 정상적인 흐름입니다.
하지만 데이터를 보여주는데 실제로 500-800ms 정도밖에 걸리지 않는다고 하더라도 스켈레톤이나 로딩 UI를 보는 순간 "아직 준비 안 됐구나" 하고 인식해 버리게 됩니다.
결국, 체감 속도를 높이기 위해서는 스켈레톤이나 로딩 UI 조차 보여주지 않는 것이 이상적이라는 결론에 도달하게 됩니다.
반복되는 페이지 이동마다 매번 API 호출?
또 하나의 이유로는 불필요한 반복 요청을 줄이기 위함입니다.
특히 사용자가 같은 페이지를 여러 번 오가는 구조일 경우에 매번 API 요청을 하게 되면 네트워크 낭비가 발생한다는 문제도 있지만, 화면이 계속 새로고침되는 느낌을 받을 수 있습니다.
그렇게 되면 당연하게도 사용자 경험 저하로 이어지게 됩니다.
이를 방지하기 위해 미리 데이터를 패칭해 캐싱해 두면 다음에 같은 페이지에 진입할 때 즉시 렌더링은 물론, 성능도 향상할 수 있습니다.
물론 반복되는 페이지가 아니더라도 사용자가 다음에 어디로 갈지, 이동 동선이 뻔한 상황이라면 더더욱 필수에 가까워집니다.
Next.js에서도 prepatching이 필요한가?
이번 글의 주제를 잡게 된 핵심 질문입니다.
SSR은 페이지가 요청되면 서버에서 데이터를 가져와 HTML을 완성한 뒤, 그걸 브라우저에 보내주는 구조입니다.
"서버에서 다 해주니까 깜빡임이나 느린 로딩도 없을 거고, 그럼 굳이 prepatching이 필요할까?"
Prepatching에 대해 생각하다 보니 문득 이런 궁금증이 생겼습니다.
SSR방식을 통해서 서버에서 미리 데이터를 내려받는데, 그렇게 되면 -미리 데이터를 패칭한다-라는 prepatching을 따로 하지 않아도 문제가 없는 거 아닐까? 하고요.
물론 이런 궁금증에 맞춰 SSR이 마법처럼 모든 문제를 해결해주지는 않았습니다.

Next.js는 사전렌더링 과정에서 서버가 브라우저에게 JS 번들 파일을 전달할 때, 모든 페이지에 필요한 JS 코드를 전달하지 않고 현재 페이지에 필요한 JS 코드만 전달합니다.
초기 접속 요청이 있을 때마다 모든 페이지의 JS 번들 파일을 전달하는 건 용량이 너무 커지게 되고, hydration 시간이 늦어져 결론적으로는 TTI가 늦어지게 되는 문제가 발생할 수 있기 때문입니다.
또한 서버에서 HTML과 데이터를 함께 내려보내더라도 hydration 이후에는 클라이언트에서 다시 데이터를 요청하거나, 내부 상태를 재구성하는 일이 발생할 수 있습니다.
그리고 이 과정에서 깜빡임이나 일시적인 데이터 공백이 발생할 수 있습니다.
App Router와 데이터 패칭
Next 13 이후 App Router 구조에서는 페이지나 레이아웃마다 generateMetadata, generateStaticParams, fetch() 기반의 서버 컴포넌트 데이터 패칭이 강조됩니다.
하지만 여전히 클라이언트 컴포넌트에서는 useEffect나 쿼리 라이브러리와 함께 데이터를 패칭해야 하는 경우가 존재합니다.
'use client';
import { useQuery } from '@tanstack/react-query';
const UserProfile = ({ id }: { id: string }) => {
const { data, isLoading } = useQuery(['user', id], () => fetchUser(id));
};예시 코드를 한 번 보면 제일 위 'use client'로 인해 클라이언트 컴포넌트라는 것을 확인할 수 있습니다.
그렇기에 당연히 SSR 시점에서 미리 데이터를 받아오는 게 불가능하고, hydration 이후에 요청이 시작됩니다.
이런 경우에 prepatching을 통해 데이터를 서버에서 먼저 가져오고 클라이언트에서 hydrate 해주는 방식이 필요합니다.
SSR과 Prepatching은 서로를 대체할 수 있는 것이 아니라, 상호 보완할 수 있는 기능이다라고 이해하시면 좋을 것 같습니다.
Prepatching의 활용법
Tanstack Query를 이용한 prepatching의 활용법을 한 번 보겠습니다.
Tanstack Query는 클라이언트에서 데이터 패칭, 캐싱, 동기화, 상태 관리 등을 매우 효율적이고 편리하게 도와주는 라이브러리입니다.
특히 React와 함께 사용하면 prepatching을 깔끔하게 구현할 수 있는 최고의 도구라고 생각합니다.
Tanstack Query의 핵심은 queryClient를 중심으로 한 쿼리 캐싱과 상태 동기화입니다.
주요 개념은
- useQuery - 데이터를 요청하고 상태를 관리하는 훅
- prefetchQuery - 데이터를 미리 요청해서 캐시에 저장
- queryClient - 쿼리를 등록하고 관리하는 중앙 객체
- dehydrate / hydrate - SSR 환경에서의 쿼리 상태 직렬화 및 복원
이렇게 네 가지를 뽑을 수 있는데, prefetchQuery에 대해서만 간단하게 알아보겠습니다.
prefetchQuery
prefetchQuery는 이름 그대로 쿼리를 미리 실행하는 함수입니다.
await queryClient.prefetchQuery({
queryKey: ['user', id],
queryFn: () => fetchUser(id),
});이렇게 캐시에 저장된 데이터는 이후 컴포넌트에서 useQuery로 접근할 때, 네트워크 요청 없이 바로 사용됩니다.
페이지 전환 전에 필요한 데이터를 미리 불러올 수 있게 해주는 핵심 API라고 할 수 있겠네요.
이를 이용하면 아래와 같은 흐름으로 prepatching을 구성하는 것이 가능합니다.
- 서버에서 queryClient.prefetchQuery로 필요한 데이터 호출
- dehydrate(queryClient)로 직렬화된 쿼리 상태 생성
- React 컴포넌트에서 <Hydrate state= { } >로 복원
- 클라이언트에서는 useQuery가 자동으로 캐시 된 데이터 인식
// 서버 컴포넌트
const queryClient = new QueryClient();
await queryClient.prefetchQuery({...});
const dehydratedState = dehydrate(queryClient);
// 클라이언트 컴포넌트
<QueryClientProvider client={queryClient}>
<Hydrate state={dehydratedState}>
<YourComponent />
</Hydrate>
</QueryClientProvider>
주의점
prefetching은 분명 UX 개선에 큰 도움이 되지만, 잘못 적용하면 오히려 중복 요청, 속도 느려짐, 비일관적 상태 등 문제가 발생할 수 있습니다.
1. 쿼리 키(Query key)는 반드시 일치시키자
Prepatching은 결국 캐시에 저장된 데이터를 재사용하는 전략입니다. 그런데 prefetchQuery에서 사용한 쿼리 키와 useQuery에서 사용하는 쿼리 키가 조금이라도 다르면, 전혀 다른 쿼리로 인식되어 재요청이 발생합니다.
prefetchQuery에서 ['user', 1], useQuery에서 ['user']
이런 상황은 흔히 키에 파라미터를 넣는 방식이 달라서 생기기 때문에, 쿼리 키를 별도로 상수화하거나 유틸로 관리하는 게 좋습니다.
2. staleTime 설정
기본적으로 Tanstack Query는 staleTime이 0이라면 즉시 데이터를 stale(오래됨) 상태로 간주하고 다시 요청합니다.
따라서 Prepatching 이후에도 useQuery가 또 요청을 보내는 현상이 생길 수 있죠.
// prefetch 이후에도 재요청이 발생하지 않도록
useQuery(['user', id], fetchUser, {
staleTime: 1000 * 60 * 5, // 5분 동안은 fresh로 간주
});정답은... 직접 경험하고, 자신의 프로젝트에 맞는 시간을 찾는 수밖에 없다고 말씀드리고 싶습니다.
최적의 정답이 정해져 있다면 좋겠지만, 프로젝트가 각기 다른 만큼 데이터와 fresh 상태의 균형을 잘 맞추는 지점을 찾아야 합니다.
3. 클라이언트와 서버의 환경 분리
Next.js의 App Router에서 Tanstack Query를 활용할 경우, 서버에서 prefetch + dehydrate, 클라이언트에서 Hydrate + useQuery가 동시에 이뤄져야 합니다. 이때 queryFn 내부에서 클라이언트 전용 API 또는 브라우저 객체(window, localStorage) 등을 사용하면 오류가 납니다.
4. Suspense 고려
Tanstack Query는 suspense: true 옵션을 지원합니다. 이걸 활용하면 isLoading 등의 상태 없이도 React의 Suspense를 통해 자동으로 fallback UI를 보여주고, 로딩이 끝나면 렌더링 하는 구조가 됩니다.
useQuery(['user', id], fetchUser, {
suspense: true,
});서버에서 prefetch 한 데이터를 Suspense fallback 없이 자연스럽게 보여주고 싶을 땐 매우 유용하지만, 에러 바운더리 처리도 함께 고려해야 합니다.
마무리
처음 Prepatching이라는 개념을 접했을 땐 “이거 그냥 요청을 좀 일찍 보내는 거 아냐?”라는 가벼운 생각이었습니다. 하지만 실제로 적용해 보니, 단순히 fetch 타이밍을 앞당기는 것 이상의 고민이 필요한 전략이라는 걸 깨달았습니다.
언제 데이터를 요청할지, 그 데이터를 어떻게 저장하고 유지할지, 클라이언트에서 이를 일관성 있게 쓸 수 있도록 연결할지를 고민하며 세 가지를 잘 어우러지도록 만들었을 때 사용자는 "빠르다", "부드럽다" 는 체감을 느낄 수 있게 됩니다.
그리고 이를 제공하기 위해 이 세가지를 잘 섞어보는 게 프론트 개발자의 항상 고민해야할 부분이겠죠.😵
항상 고민하고 좋은 성능을 위해 절대 잊지 말아야 할 부분이라고 생각하며, 항상 이를 잊지 않고 고민하는 자세를 가져봅시다.
출처
'Framework > Next.js' 카테고리의 다른 글
| Next.js에서의 페이지 이동 방식 (0) | 2025.06.17 |
|---|---|
| SEO. 그게 어떻게 돌아가는 건데? (3) | 2025.01.22 |
| Next.js란 무엇인고 (0) | 2025.01.20 |