

1. 디스크 스케줄링
디스크 스케줄링은 디스크 I/O 요청을 처리하는 순서를 결정하는 운영체제의 알고리즘입니다.
디스크 장치의 경우, 메모리처럼 직접 접근은 불가능하고 데이터를 읽기 위해서는 디스크 헤드를 물리적으로 이동시켜야 합니다.
그리고 이 과정에서 가장 많은 시간이 소요되는 것이 Seek Time (탐색 시간)입니다.
하드디스크는 여러 요청이 동시에 들어오는 경우가 많고, 이 요청들을 아무 순서나 처리하면 디스크 헤드가 들쭉날쭉 이동하게 되어 전체 처리 시간이 비효율적으로 증가합니다.
따라서 운영체제는 디스크 스케줄링 알고리즘을 이용해 요청 순서를 최적화하고, 디스크 헤드의 이동을 줄이는 방향으로 성능을 향상합니다.
왜 필요할까?
- 디스크는 느립니다.
: 디스크는 메모리보다 훨씬 느린 장치이며, 디스크 레드의 물리적 이동은 병목의 주요 원인입니다 - 요청이 동시에 들어올 수 있습니다,
: 여러 프로세스가 동시에 I/O를 요청할 수 있기 때문에, 순서를 어떻게 정하느냐에 따라 성능 차이가 커집니다 - 비효율적인 순서는 전체 시스템 속도 저하로 이어집니다.
: 비효율적으로 이리저리 왔다 갔다 하면 한 요청당 수 밀리초의 차이가 생기며 전체 응답 속도와 시스템 부하에 영향을 줍니다.
2. 디스크 구조와 I/O
디스크 스케줄링을 이해하기 위해서는 디스크의 물리적 구조와 데이터 접근 방식에 대해 어느 정도는 알고 있을 필요가 있습니다.😗
스케줄링에 대해 알아보기 전에, 용어 정리부터 빠르게 하고 들어가 보겠습니다.
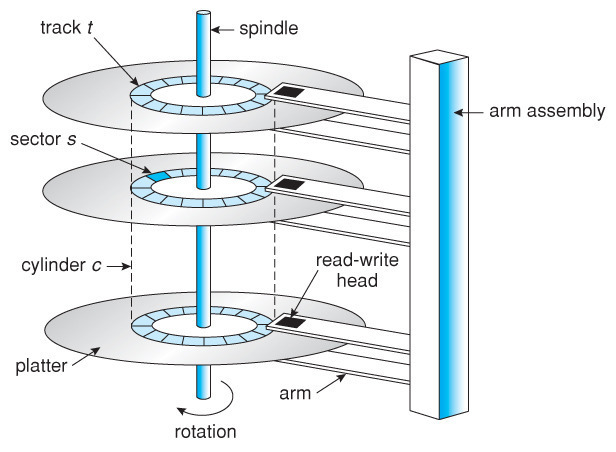
디스크 기본 구조
- 트랙(Track)
디스크의 표면을 동심원 모양으로 나눈 원형 경로.
데이터를 저장하는 기본 단위 중 하나 - 섹터(Sector)
하나의 트랙을 다시 조각내어 나눈 단위.
보통 512B - 4KB 정도의 데이터를 담습니다. - 실린더(Cylinder)
같은 반지름을 가지는 트랙들을 수직으로 연결한 개념.
여러 플래터(원판)에서 동일 위치의 트랙들이 하나의 실린더를 이룹니다. - 디스크 헤드(Disk Head)
데이터를 읽고 쓰기 위해 트랙 위를 이동하는 장치.
이 헤드가 움직이는 데 시간이 많이 소요됩니다.
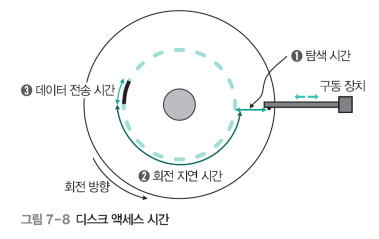
시간 요소
- 탐색 시간(Seek Time)
디스크 레드가 원하는 트랙으로 이동하는 데 걸리는 시간.
→ 디스크 스케줄링 알고리즘은 바로 이 시간을 줄이는 것을 핵심으로 합니다. - 회전 지연(Rotational Latency)
원하는 섹터가 디스크 헤드 아래로 올 때까지 디스크가 회전하는 데 걸리는 시간. - 전송 시간(Transfer Time)
데이터를 실제로 읽거나 쓰는 데 걸리는 시간
대부분의 디스크 I/O 성능 병목은 탐색 시간과 회전 지연에서 발생하며, 이를 최소화하는 것이 스케줄링의 핵심입니다.
3. 디스크 스케줄링 알고리즘
디스크 스케줄링은 앞에서 설명했듯이, 디스크 헤드의 이동 거리와 처리 시간을 줄이기 위한 방법입니다.
사용할 데이터가 디스크의 여러 곳에 저장되어 있을 때 데이터를 액세스 하기 위해 디스크 헤드의 이동 경로를 결정하는 방법이라고 보시면 될 것 같습니다.
FCFS (First-Come, First-Served)
첫 번째로 알아볼 것은 바로 FCFS입니다.
이름에서 볼 수 있듯, 처음으로 온 것이 처음으로 처리된다. 즉, 요청이 들어온 순서대로 처리되는 알고리즘입니다.
좀 더 익숙한 이름인 FIFO(First In, First Out)과 비슷한 녀석이라고 볼 수 있겠네요.
단순한 알고리즘인 만큼 구현이 간단하지만, 그만큼 헤드가 움직여야 하는 거리가 많습니다.
요청 순대로 처리를 해주는 게 공평해 보이기는 하지만, 그만큼 비효율적인 방법이기도 합니다.
예시 문제를 보며 좀 더 이해해 보도록 합시다!
Q. FCFS 기법을 사용할 경우 디스크 대기 큐의 작업들을 수행하기 위한 헤드의 이동 순서와 총 이동 거리는?
(단, 초기 헤드의 위치는 50이다)

- 이동 순서 : 50 → 100 → 150 → 20 → 120 → 30 → 140 → 60 → 70 → 130 → 200
- 총 이동거리 : 50 + 50 + 130 + 100 + 90 + 110 + 80 + 10 + 60 + 70 = 750
SSTF (Shortest Seek Time First)
이 녀석은 탐색 거리가 가장 짧은 트랙에 대한 요청을 먼저 처리하는 기법입니다.
현재 헤드 위치에서 가장 가까운 거리에 있는 트랙으로 헤드를 이동하며 처리하기 때문에 FCFS 기법보다는 헤드의 움직임이 훨씬 줄어듭니다.
다만 몇 가지 특징과 단점을 살펴보자면...
- 가운데 트랙이 안쪽이나 바깥쪽 트랙보다 서비스의 모듈 확률이 높습니다
- 헤드에서 멀리 떨어진 요청은 기아 상태(무한 대기 상태)가 발생할 수 있습니다
- 일괄 처리 시스템에는 유용하나, 응답 시간의 편차가 크기 때문에 대화형 시스템에는 부적합합니다
이 녀석도 예시를 보며 이해해 보겠습니다.
Q. SSTF 기법을 사용할 경우 디스크 대기 큐의 작업들을 수행하기 위한 헤드의 이동 순서와 총 이동 거리는?
(단, 초기 헤드의 위치는 50이다)
- 이동 순서 : 50 → 60 → 70 → 100 → 120 → 130 → 140 → 150 → 200 → 30 → 20
- 총 이동거리 : 10 + 10 + 30 + 20 + 10 + 10 + 10 + 50 + 170 + 10 = 330
총 이동거리를 보시면 FCFS 기법보다 총 이동거리가 무려 절반으로 줄어든 것을 확인하실 수 있습니다.
다만, 위에서 말했던 기아 상태가 발생할 수 있다는 단점 때문에 공평성 문제를 크게 위반하여 잘 쓰이지 않는 방식이기는 합니다.
SCAN
SCAN 알고리즘은 현재 진행 중인 방향으로 가장 짧은 탐색 거리에 있는 요청을 먼저 처리하는 기법으로, 트랙의 끝부터 끝까지 이동하며 서비스를 제공합니다.
SSTF의 문제점인 응답 시간의 편차를 극복하기 위해 개발된 녀석입니다.
특징으로는, 헤드는 이동하는 방향의 앞쪽에 I/O 요청이 없을 경우에만 후퇴(역방향)가 가능하다는 점을 뽑을 수 있습니다.
Q. SCAN 기법을 사용할 경우 디스크 대기 큐의 작업들을 수행하기 위한 헤드의 이동 순서와 총 이동 거리는?
(단, 진행 방향은 바깥쪽, 초기 헤드의 위치는 50이다)
- 이동 순서 : 50 → 30 → 20 → 0 → 60 → 70 → 100 → 120 → 130 → 140 → 150 → 200
- 총 이동거리 : 20 + 10 + 20 + 60 + 10 + 30 + 20 + 10 + 10 + 10 + 50 = 250
여기서 확인하실 수 있듯이, 처음 시작 위치에서 진행 방향에 위치한 큐 중 가장 짧은 탐색거리에 있는 요청을 먼저 처리합니다.
그리고 해당 방향으로 쭉 이동해 트랙의 끝(0)을 찍고, 그다음 역방향으로 트랙의 끝(200)까지 이동해 처리하는 것을 확인할 수 있습니다.
C-SCAN
C-SCAN은 SCAN 알고리즘 앞에 C-(Circular)가 붙은 알고리즘입니다. 즉, SCAN을 조금 수정한 버전이라고 보시면 됩니다.
항상 한 방향으로 움직이면서 가장 짧은 탐색 거리를 찾도록 처리하는 기법입니다.
헤드는 트랙의 바깥쪽에서 안쪽으로 한 방향으로만 움직이며, 안쪽보다 기회가 적은 바깥쪽의 시간 편차를 줄입니다.
Q. 안쪽보다 바깥쪽이 기회가 적다는 게 무슨 말인가요?
A. SCAN으로 잠시 되돌아가서 살펴봅시다.
SCAN 알고리즘은 스캔과정에서 트랙의 끝까지 이동하기 때문에, 끝 쪽 트랙은 한 번씩 방문하는 반면, 안쪽 트랙들은 두 번씩 방문하게 되는 불합리가 발생하게 됩니다.
이 문제점을 해결하기 위해, 한쪽 끝에 도달하면 반대로 돌아올 때는 서비스를 하지 않고 이동만 하는 알고리즘입니다.
Q. C-SCAN 기법을 사용할 경우 디스크 대기 큐의 작업들을 수행하기 위한 헤드의 이동 순서와 총 이동 거리는?
(단, 진행 방향은 항상 바깥쪽에서 안쪽으로 고정하며, 초기 헤드의 위치는 50이다)
- 이동 순서 : 50 → 60 → 70 → 100 → 120 → 130 → 140 → 150 → 200 → 0 → 20 → 30
- 총 이동거리 : 10 + 10 + 30 + 20 + 10 + 10 + 10 + 50 + 200 + 20 + 10 = 380
이동 순서를 보시면, 200 큐에서 곧바로 0으로 헤드가 움직이게 됩니다.
200과 0 사이에 20과 30 큐가 있었는데도 불구하고 말이죠.
이처럼 반대로 돌아올 때는 서비스를 하지 않고 이동만 하는 스케줄링 방법이라고 보시면 됩니다.
N-Step SCAN
N-Step 스케줄링은 진행 도중 도착한 요청을 일정 개수(N개)씩 잘라 고정된 묶음 단위로 SCAN 알고리즘을 수행하며 다음 방향으로 진행할 때 최적의 서비스를 처리하는 기법입니다.
이는 SCAN의 무한 대기 발생 가능성을 제거한 것으로, 특정 방향의 진행이 시작될 경우에 대기 중이던 요청들만 서비스합니다.
SCAN보다는 응답 시간의 편차가 적고, 진행 방향의 요청을 서비스한다는 특징이 있습니다.
Q. N-Step SCAN 기법을 사용할 경우 디스크 대기 큐의 작업들을 수행하기 위한 헤드의 이동 순서와 총 이동 거리는?
(단, N = 5로 가정하며, 초기 헤드의 위치는 50, 150이다)
- 1번 묶음 큐 : 100, 150, 20, 120, 30
- 2번 묶음 큐 : 140, 60, 70, 130, 200
- 이동 순서 : 50 → 100 → 120 → 150 → 200 → 140 → 130 → 70 → 60 → 30 → 20
- 총 이동거리 : 50 + 20 + 30 + 50 + 60 + 10 + 60 + 10 + 30 + 10 = 330
LOOK / C-LOOK
LOOK
SCAN 알고리즘 기법을 기반으로 사용합니다.
SCAN 방식에서는 트랙 요청이 없어도 헤드가 맨 마지막 트랙(0번이나 가장 마지막 트랙)까지 도착한 후에 방향을 바꿉니다.
하지만 LOOK 기법은 SCAN 방식을 사용하지만 더 이상 서비스할 트랙이 없으면 헤드가 끝까지 가지 않고 중간에서 방향을 바꿉니다. 다른 한쪽 끝에 도달하면 역 방향으로 이동하면서 오는 길에 있는 요청을 처리하기 때문에 엘리베이터처럼 왕복하며 처리하므로 엘리베이터 스케줄링이라고도 부릅니다.
디스크 암(Disk Arm)
디스크상에 기억되어 있는 레코드에 접근하여 읽고 쓰기 위하여 헤드를 디스크면상의 위치로 이동시키기 위해 사용되는 기구
잠시 SCAN 기법의 예시를 들고 오겠습니다.
Q. SCAN 기법을 사용할 경우 디스크 대기 큐의 작업들을 수행하기 위한 헤드의 이동 순서와 총 이동 거리는?
(단, 진행 방향은 바깥쪽, 초기 헤드의 위치는 50이다)
- 이동 순서 : 50 → 30 → 20 → 0 → 60 → 70 → 100 → 120 → 130 → 140 → 150 → 200
- 총 이동거리 : 20 + 10 + 20 + 60 + 10 + 30 + 20 + 10 + 10 + 10 + 50 = 250
여기서 SCAN 기법일 경우에는 20에서 0을 찍고, 60으로 돌아갑니다.
그러나 LOOK기법일 경우에는 0을 찍는 과정이 사라지고 20에서 60으로 간다고 보시면 됩니다.
C-LOOK
C-SCAN 알고리즘 기법을 사용하며 각 요청에 걸리는 시간을 좀 더 균등하게 하기 위한 SCAN의 변형입니다.
간단하게 말하면 그냥 C-SCAN 디스크 스케줄링의 LOOK 버전이라고 보시면 됩니다.
SCNA과 같이 C-SCAN은 한쪽 방향으로 헤드를 이동해 가면서 요청을 처리하지만 한쪽 끝에 다다르면 반대 방향으로 헤드를 이동하며 처리하는 것이 아니라 처음 시작했던 자리로 다시 되돌아가서 서비스를 시작합니다.
C-SCAN 스케줄링 알고리즘은 실린더들을 마지막 실린더가 처음 실린더와 맞닿은 원형 리스트로 간주합니다.
출처
'CS > 운영체제' 카테고리의 다른 글
| 메모리 관리 전략 (1) | 2025.02.13 |
|---|---|
| 프로세스 동기화 - 상호배제 기법 (0) | 2025.02.11 |