
쓰다 보니 프로젝트 회고가 되어버린 Presigned URL 업로드 포스트....
하지만 기억을 되짚어 보며 복습도 되고 좋네요 ^-^b

Presigned URL이란?
웹 어플리케이션을 개발하면서 파일을 업로드해야 할 경우가 생기면 여러분은 어떤 방식을 이용하나요?
아마 가장 먼저 떠오르는 방법은 파일을 서버에 올리고, 서버를 거쳐 파일을 S3에 업로드하는 방식을 떠올리실 거라 생각합니다.🤔
그러나 이 방식에 불필요한 서버 부하와 비효율적인 네트워크 사용이라는 문제가 있습니다.
바로 이 문제를 해결하기 위해 Presigned URL이 등장헀습니다.
그래서 정확히 Presigned URL이 뭐냐고 물으신다면. 정말 말 그대로 미리발급된(Presigned) URL이라고 생각하시면 됩니다.
잠시 AWS에서 정의한 Presigned URL의 정의를 한 번 같이 살펴보실까요?
미리 서명된 URL을 사용하여 버킷 정책을 업데이트하지 않고도 Amazon S3의 객체에 시간제한 액세스를 부여할 수 있습니다. 미리 서명된 URL은 브라우저에 입력하거나 프로그램에서 객체를 다운로드하는 데 사용할 수 있습니다. 미리 서명된 URL에서 사용하는 자격 증명은 URL을 생성한 AWS 사용자의 자격 증명입니다.
또한 미리 서명된 URL을 사용하여 다른 사람이 특정 객체를 Amazon S3 버킷에 업로드하도록 허용할 수도 있습니다. 이 경우 상대방에게 AWS 보안 자격 증명이나 권한이 없어도 업로드할 수 있습니다. 미리 서명된 URL에 지정된 것과 동일한 키를 가진 객체가 버킷에 이미 존재하는 경우 Amazon S3는 기존 객체를 업로드한 객체로 대체합니다.
이것이 바로 AWS 문서에 들어가면 볼 수 있는 Presigned URL에 대한 정의입니다.
Presigned URL은 제한된 시간 동안 특정 객체에 대한 액세스를 허용하는 임시 URL입니다. 라고 말해도 아시는 분은 이해가 되겠지만 이 개념에 대해 처음 듣는 분이시라면 [이것 뭐에요?] 상태가 될 수 있다 생각합니다.
그럼 풀어서 설명을 해 봅시다.
쉽게 말해 1. 백엔드에서 인증된 URL을 생성해서 클라이언트에게 제공하면, 2. 프론트엔드가 이 URL을 사용해 AWS S3에 직접 파일을 업로드할 수 있는 방식입니다.
즉 기존에 파일을 서버에 보내고 서버에서 알아서 처리하는 방식이 아닌, Presigned URL을 통해 프론트엔드가 바로 업로드할 수 있다는 말이죠!
Presigned URL의 흐름
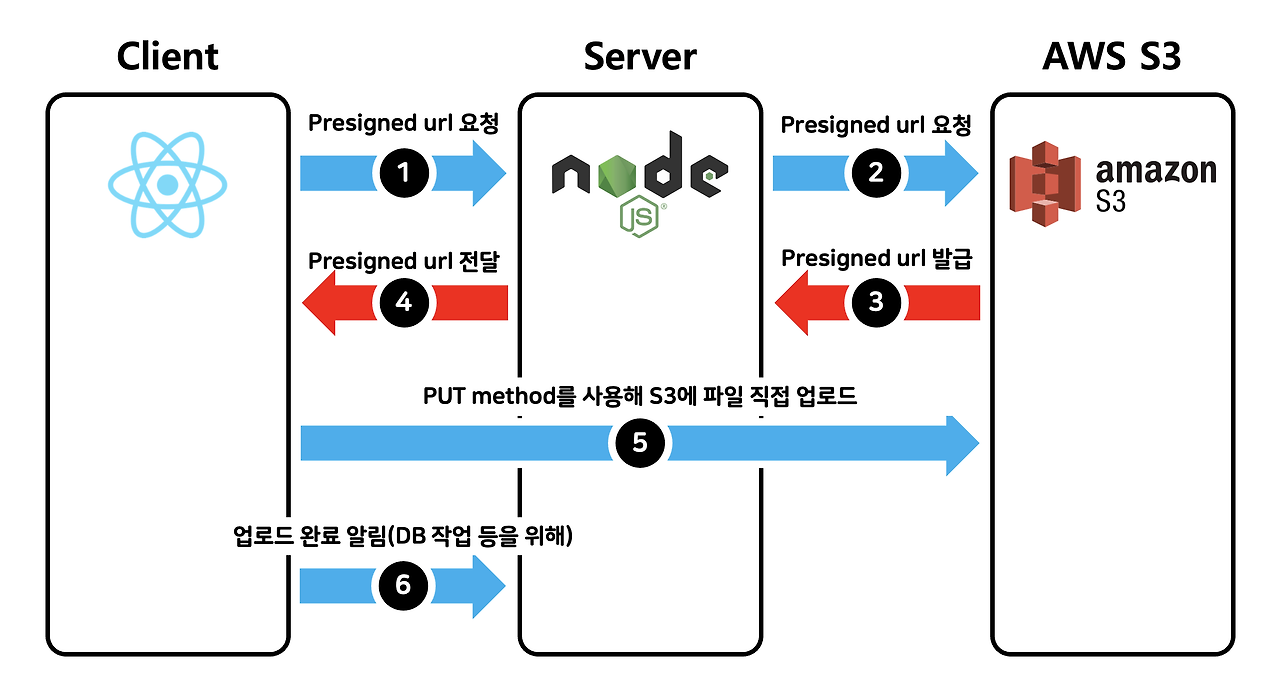
위의 이미지를 통해 대충 어떤 흐름으로 가는지 예측하셨을 수도 있겠네요.
나중에 코드를 보면서 좀 더 자세히 살펴보겠지만, 일단 전체적인 흐름은 다음과 같습니다.
- 프론트 : 사용자가 파일을 선택하면 백엔드에 Presigned URL 발급 요청
- 백 : S3에 요청하여 해당 파일을 업로드할 Presigned URL을 생성 후 반환
- 프론트 : Presigned URL을 사용해 S3에 파일 직접 업로드
- 프론트 : 업로드 후 업로드된 파일 URL을 서버에 저장 또는 사용자에게 표시
그러나 제가 이해했을 때는 이런 설명을 듣고 이해하지 않았습니다.
제가 백엔드 팀원의 설명을 들으면서

이 얼굴로 바라보니 친절하게 저에게 맞는 맞춤형 설명을 해주었습니다......ㅋㅋ....
들어준 예시는 바로 택배 보내기였습니다.
저희가 택배를 보낼 때는 (물건을 택배에 포장한다) (보낼 곳에 대해 송장을 떼 온다) (송장을 붙이고 택배를 보낸다)
이 세 단계를 거쳐 택배를 보냅니다.
Presigned URL을 사용하는 과정은 택배를 보내는 것과 동일하다고 생각하면 됩니다.
저희(Client)가 어디로 보낼 건지, 받는 사람은 누군지, 정보를 써서 우체국 직원(Server)에게 보여주면
직원이 아하! 하고 그 장소에 대한 송장(Presigned URL)을 써서 저에게 줍니다.
그럼 저는 그냥 택배에 송장만 붙이고 보내는 것이죠!
왜 Presigned URL을 사용하는 걸까
자, 그럼 프론트엔드에서 바로 업로드를 하는 이 Presigned URL 방식에는 어떤 이점이 있을지 살펴봅시다.
서버 부하 감소 / 비용 절감 / 빠른 업로드
세 가지 전부 한 개의 장점에서 뻗어 나오기 때문에 한 번 묶어보았습니다.
기존에 사용했던 방식은 파일이 클라이언트→서버→S3의 순서로 이동하기 때문에 모든 파일이 백엔드를 거쳐야 했습니다.
그러나 이미지 업로드는 매우 부하가 큰 작업인 만큼 백엔드를 거치면 서버가 금방 죽을 수도(×_×.. 있습니다.
이게 아니라면 동시 업로드 요청 수를 제한해야 하는데 이러면 유저 경험이 떨어지게 되겠죠.
하지만 Presigned URL을 사용하면 클라이언트→S3로 직접 업로드할 수 있어 서버를 거치는 단계가 사라집니다.
그 결과 서버 부하가 감소한다는 이점을 얻을 수 있습니다.
-----------------------
이것도 위에 설명했던 것의 부가적인 장점이라 볼 수 있습니다.
AWS에서 서버→S3로 전송하는 트래픽 비용이 사라지면서 서버 트래픽 비용을 절감할 수 있습니다.
-----------------------
당연하게도, 서버를 거치지 않기 때문에 속도가 훨씬 빨라집니다.
특히 대량 파일 업로드나 영상/이미지 업로드 서비스에서 유용하게 사용할 수 있습니다.
보안 강화
Presigned URL의 장점 중 하나로, 일정 시간 후에 자동 만료되는 시간제한 액세스입니다.
그렇기 때문에 혹여나 URL이 외부에 유출되는 불상사가 발생하더라도 만료로 인해 장기적으로 사용될 수 없기 때문에 보안을 강화할 수 있습니다.
또한 특정 사용자만 업로드를 허용하는 등의 권한을 세밀하게 제어 가능하다는 장점도 있습니다.
코드와 함께 S3 업로드 방법 별 차이를 알아보자.
저는 다양한 프로젝트에 참여하면서 그동안 파일을 참 다양하게도 서버에 올려보았는데요🥸
총 세 가지 단계에 걸쳐 Presigned URL을 사용하는 쪽으로 진화해 왔습니다.
클라이언트→서버→S3 / 클라이언트→S3 (presigned url X) / 클라이언트→S3 (presigned url O)
제일 처음에는 클라이언트→서버→S3를 먼저 사용하고 있었습니다.
그러다 서버를 거치면서 부하도 걸리고, 속도도 느려지니까 이런 생각을 하게 됩니다.
서버를 거치는 단계가 필요 없이 부하를 늘리는 거면, 그냥 바로 S3로 쏘면 되지 않아?
저와 백엔드 팀원은 곧바로 실천에 들어갑니다.
AWS.config.update({
region: "ap-northeast-2",
accessKeyId: ACCESS_KEY,
secretAccessKey: SECRET_ACCESS_KEY,
});
const upload = new AWS.S3.ManagedUpload({
params: {
ACL: "public-read",
Bucket: "blurrr-img-bucket",
Key: `images/${filename}`,
Body: file,
ContentType: file.type,
},
});그 결과가 바로 이 녀석입니다.
프론트에서 액세스 키를 가지고, 바로 S3로 보내버리는 만행을 저지릅니다.
이게 왜 만행이냐 물으신다면...
개발자라면 공통적으로 주의해야 하는 사항이 있습니다.
바로 우리의 클라이언트들은 어디로 뛰쳐나갈지 모르는 예측 불가한 행동 방식을 가지고 있다는 것을요.
만약 클라이언트가 엄청나게 큰 파일을 보내버리거나, 잘못된 파일을 올려도 그냥 S3에 올려버리게 되는 겁니다.
(물론 처리는 하겠지만, 위험 요소를 추가시켜 버리는 꼴이죠)
백엔드는 프론트엔드를, 프론트엔드는 클라이언트를 항상 의심해야 합니다.
그래서 나온 녀석이 Presigned URL입니다.
const newFileName = generateFileName(file.name);
const renamedFile = new File([file], newFileName, { type: file.type });
const presignedData = await videoPresigned(renamedFile.name);
const uploadURL = presignedData.fullUrl;
const noQueryParamUrl = presignedData.noQueryParamUrl;
await S3UploadVideo(uploadURL, renamedFile);
setVideoFiles(prevFiles => [...prevFiles, renamedFile]);
setNoQueryParamURLs(prevUrls => [
...prevUrls,
{ videoOrder: prevUrls.length + 1, videoUrl: noQueryParamUrl }
]);좀 복잡해 보이지만 흐름은 단순합니다.
먼저 renamedFile을 이용해 새로 정의한 파일의 이름을 videoPresigned로 보내 Presigned URL을 요청했습니다.
이 파일 이름을 보낼 거니까, 이거 송장 떼줘. 라고 요청한 거죠. 그리고 그 URL을 uploadURL에 저장합니다.
여기서 uploadURL과 noQueryParamUrl 두 개를 받아오는 코드가 있는데
uploadURL은 S3에 파일을 업로드하는 데 사용할 URL입니다.
그리고 noQueryParamUrl은 서버에 저장할 S3에 저장된 파일의 주소입니다.
나중에 업로드한 파일을 계속 확인해야 하는데, URL만 알고 있으면 이후에 접근도 빠르게 할 수 있으니까요.
이 과정을 통해 서버에 업로드가 끝나면 서버는 클라이언트가 요청할 때마다 저장한 noQueryParamUrl만 보내서 조회를 가능하게 합니다.
중요하진 않지만 녹음 파일을 다루었던 Presigned URL도 한 번 올려봅니다..^-^
const data = await getPresignedUrl();
const objectUrl = data.object_url;
// Blob을 File 객체로 변환
const wavFile = new File([blob], "record.wav", {
type: "audio/wav",
});
if (!objectUrl) {
return;
}
await S3UploadRecord(data.presigned_url, wavFile);
// 서버로 녹음된 파일 정보 저장
await saveRecordedFile(note_id, objectUrl, pageMovementRef.current);
백엔드 입장에서 보는 Presigned URL
백엔드는 잘 모르기도 하지만, 제 코드가 아니기 때문에.. 조금만 가져와봤습니다.
GeneratePresignedUrlRequest generatePresignedUrlRequest = getGeneratePresignedUrlRequest(bucket, fileName);
URL url = amazonS3.generatePresignedUrl(generatePresignedUrlRequest);
Map<String, String> result = new HashMap<>();
result.put("fullUrl", url.toString());
result.put("noQueryParamUrl", "https://" + url.getHost() + url.getPath());
return result;프론트가 요청을 하면 Presigned URL 요청 객체와 URL을 생성하고, 이 응답 데이터를 저장할 Map객체를 생성합니다.
그리고 fullUrl(위 코드에서 uploadUrl과 동일)에는 presigned url을 저장하고,
S3 저장 파일을 확인할 수 있도록 https 추가등의 설정을 한 noQueryParamUrl도 Map객체에 담아, 프론트 요청에 대한 응답으로 반환합니다.
마무리 & 고민
쓰다 보니 새로운 지식을 얻기보다는 제 프로젝트에 대해 회고하고, 코드를 뜯어보며 제가 고민했던 흐름을 되짚어 보는 시간이었던 것 같습니다.
위 코드는 한 프로젝트의 예시만 작성했지만, 실제로는 여러 프로젝트에서 presigned url을 다루며 많이 고민하기도 했습니다.
처음에는 1.presigned 요청 2. S3에 업로드라는 2번의 api 요청으로 인해 진짜 좋은 게 맞나?라는 고민도 들기도 했고
파일이 여러 개 올라갈 수도 있는데 그럼 하나의 파일마다 api를 계속 요청해야 하는 문제도 직면한 경험이 있습니다.
물론 무조건 단일로 이루어지는 게 아니라 여러 파일에 대한 정보를 배열 형태로 요청해서 한 번에 해결하는 방식으로 해결했지만 말이에요.
그리고 단순히 업로드를 했다고 끝이 아니라,
1. 게시글 작성 로직이었는데, 파일을 업로드하자마자 S3에 업로드해버리면 실제로는 글을 올리지 않아도 S3에 파일이 저장되어 메모리가 낭비되는 경우
2. 만약 파일의 크기가 큰 경우 아직 S3에 업로드가 완료되지 않았는데, 서버에는 S3의 주소를 저장해서 조회 오류가 나는 경우
등등..
수많은 시행착오와 해결한 문제도, 해결하지 못한 문제도 많았습니다.
나중에 또 시행착오를 겪으면 여기 하나씩 추가해 보도록 하겠습니다ㅋㅋ
출처
'Frontend' 카테고리의 다른 글
| [디자인 패턴] MVC / MVP / MVVM 패턴 (0) | 2025.04.16 |
|---|---|
| 주소창에 google.com 입력시 일어나는 일 (0) | 2025.04.10 |
| Tanstack Query와 Next.js fetch. 뭘 사용해야 할까? (0) | 2025.04.02 |
| SSE(Server-Sent Event) : 서버야 네가 알려줘 (1) | 2025.02.06 |